
Malicious AI models are transforming the cybersecurity ecosystem, giving adversaries the ability to scale, adapt, and innovate attacks like never before. Unlike traditional cyber tools, these AI models are designed to learn and evolve, improving their effectiveness over time. They can generate everything from phishing emails that mimic the victim’s tone to polymorphic malware capable of rewriting itself to evade detection.
The growing availability of AI-as-a-Service platforms on the dark web accelerates this trend. Cybercriminals now have access to tools that automate reconnaissance, exploit vulnerabilities, and even craft custom payloads tailored to specific targets. These malicious models are often optimized to mimic legitimate applications, making them challenging to identify using conventional detection methods. Read on to find out what this looks like in the real world and how deception technology can fight against them.
Real-world examples of malicious AI models in action
One concerning example involves AI used to generate deepfake videos for extortion. Attackers create realistic videos of public figures engaging in fabricated activities, then use these to blackmail individuals or sow misinformation. Another case saw AI-driven phishing tools generate thousands of unique, context-aware emails within minutes, bypassing spam filters that rely on pattern recognition.
More real-world examples
/ Phishing Evolution: AI-powered phishing tools craft personalized messages that mimic the tone, style, and context of legitimate communications, bypassing spam filters.
/ Polymorphic Malware: AI develops malware capable of altering its code structure to evade detection by signature-based antivirus systems.
/ Deepfake Misinformation: A Malicious AI generates realistic audio or video content to impersonate leaders, spread false information, or disrupt operations.

Malicious AI models: The bottom line
The proliferation of malicious AI models shifts the balance of power in cybersecurity. Attackers can now launch campaigns that are both highly personalized and scalable, challenging defenders to address threats at an unprecedented pace. These tools democratize advanced attack capabilities, enabling even less technically skilled adversaries to carry out complex operations. For defenders, this means not only countering these tools but also anticipating their evolution.
Your AI cybersecurity defense against malicious AI models
A novel defense strategy against malicious AI models involves AI poisoning, where decoy content is deliberately planted on the public or dark web. This approach leverages the fact that large language models (LLMs), including malicious ones, rely on publicly available data to learn and evolve. By publishing misleading information—such as fabricated vulnerabilities or fake infrastructure details about a target organization—defenders can manipulate the responses these models provide to attackers.
When an adversary queries a compromised or malicious LLM, the model would then supply false information intentionally designed to redirect them to a deception environment. This controlled space acts as a breadcrumb trail, enticing attackers to interact with systems where their actions can be monitored, analyzed, and mitigated. The poisoned data essentially functions as a trap that only malicious LLMs will use, as legitimate AI systems are often programmed to avoid responding to harmful or sensitive queries. CounterCraft’s threat intelligence technology, powered by deception, has the tools you need to craft this type of campaign to fight malicious AI models.
Using poisoned LLMs to attract adversaries to deception environment
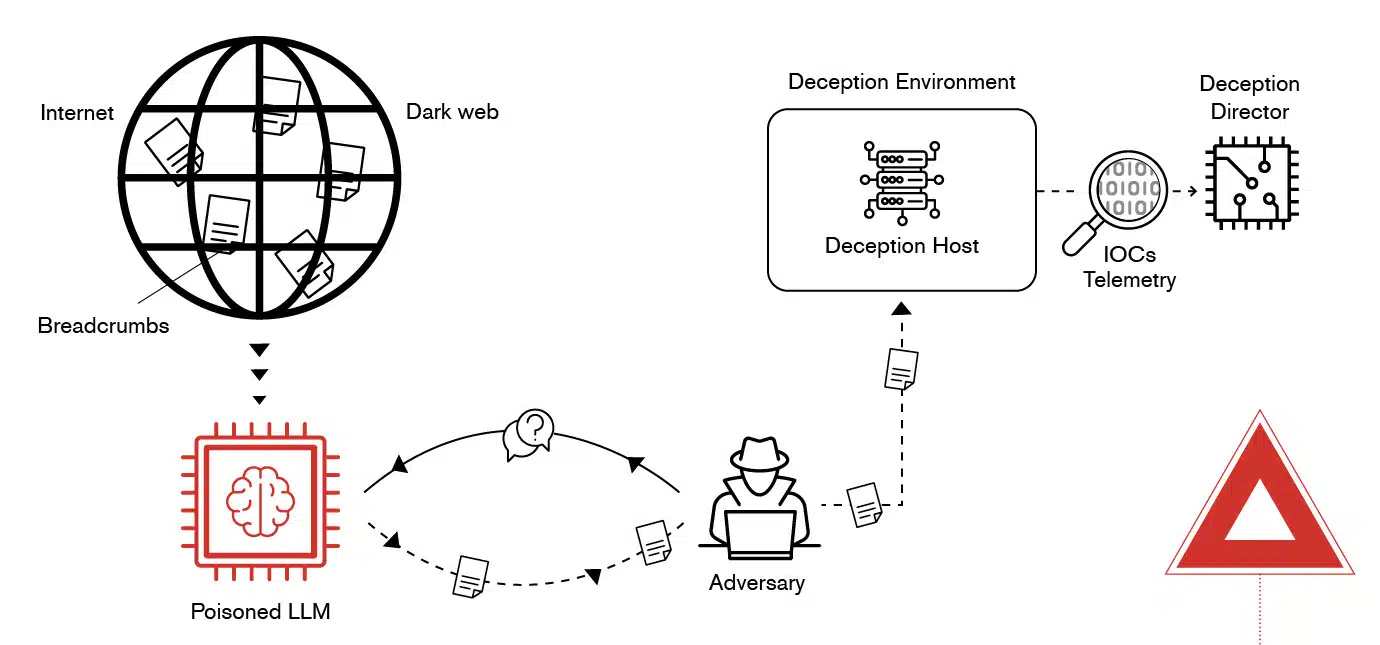
This strategy highlights the significant distinction between “good” and “bad” LLMs. Legitimate models incorporate safety measures and censorship to avoid generating responses to harmful prompts, such as instructions for building bombs or creating illegal substances. In contrast, malicious LLMs lack these restrictions and will answer such queries because they are trained on uncensored or open-source data. This makes them more susceptible to consuming and acting on deception content planted by defenders.
A core component of this approach is understanding the training mechanisms of LLMs. Malicious models scan and assimilate vast amounts of internet data, including deception content, which defenders can strategically introduce to disrupt their effectiveness. The goal is to create scenarios where malicious models consistently return inaccurate or misleading results, complicating the efforts of adversaries who rely on them for reconnaissance or operational planning.
This concept aligns with the broader goal of turning malicious AI tools against their users, using their dependence on uncensored learning to neutralize their threat. It’s a practical, innovative method to detect and counteract malicious AI activity happening today.

Find out more
To learn more about how innovative AI defense strategies like AI poisoning can outsmart malicious models and strengthen your organization’s cybersecurity, get in touch with one of our experts.
If you’d like to read about more of the latest AI threats to cybersecurity, download our ebook,From Poisoned Data to Secure Systems: The Antidote to Navigating AI Threats today.