
Prompt injection attacks exploit the mechanisms AI systems use to interpret and respond to user inputs. Attackers craft inputs such as specific queries or commands that manipulate AI systems into bypassing safety protocols or executing unintended actions. As AI becomes more deeply embedded in critical processes like customer service, financial transactions, and even software development, prompt injection emerges as a highly impactful threat.
These attacks are particularly concerning because they don’t rely on sophisticated threat-attacking skills. Instead, attackers manipulate the AI’s logic by exploiting gaps in its natural language understanding. A well-crafted prompt can cause a chatbot to expose sensitive customer data, execute unauthorized actions, or produce malicious outputs.
The simplicity of these attacks makes them a preferred method for attackers looking to exploit AI systems.
Real-world examples of exploitation of AI systems via prompt injection
Despite safeguards, AI systems remain vulnerable to prompt injection attacks—where adversaries craft decoys to manipulate responses. These real-world cases highlight how attackers have successfully exploited AI-powered tools to extract confidential data, generate harmful code, and bypass security measures. Understanding these threats is crucial for strengthening AI defenses and mitigating risks.
/ Chatbot Data Leakage: Attackers manipulated a financial services chatbot into disclosing confidential account information through carefully phrased queries.
/ Development Tool Exploits: Prompt injection attacks tricked AI-powered coding assistants into generating harmful scripts under the guise of legitimate code.
/ Confidential Data Extraction: An AI assistant trained on proprietary documents was exploited to reveal sensitive company strategies.

Exploitation of AI via prompt injection : The bottom line
Prompt injection attacks target the trust organizations place in AI’s decision-making capabilities. As AI systems increasingly handle sensitive tasks, attackers exploiting these vulnerabilities can compromise security, expose proprietary data, and undermine trust in AI deployments. This threat highlights the need for organizations to rethink how they design, test, and secure AI interactions.
Your AI cybersecurity defense against exploitation of AI models via prompt injection
To counter this threat, a novel approach involves creating a deception environment in the form of a controlled, monitored space where attackers believe they are interacting with a legitimate LLM but are instead engaging with a digital twin. This duplicate model mimics the real LLM in production but operates in an isolated, on-premises or cloud-secured setting.
This deception-based strategy serves two key functions:
- Containment: Attackers are trapped within a monitored environment, preventing them from affecting real systems.
- Threat Intelligence Collection: The system tracks and records the attacker’s tactics, techniques, and procedures (TTPs), generating valuable insights for threat detection and response.
The deception strategy incorporates honeypots—simulated environments designed to attract attackers. These AI-powered honeypots resemble real-world LLM implementations, tricking adversaries into interacting with a false target.
Using prompt injection attacks to attract adversaries to deception environment
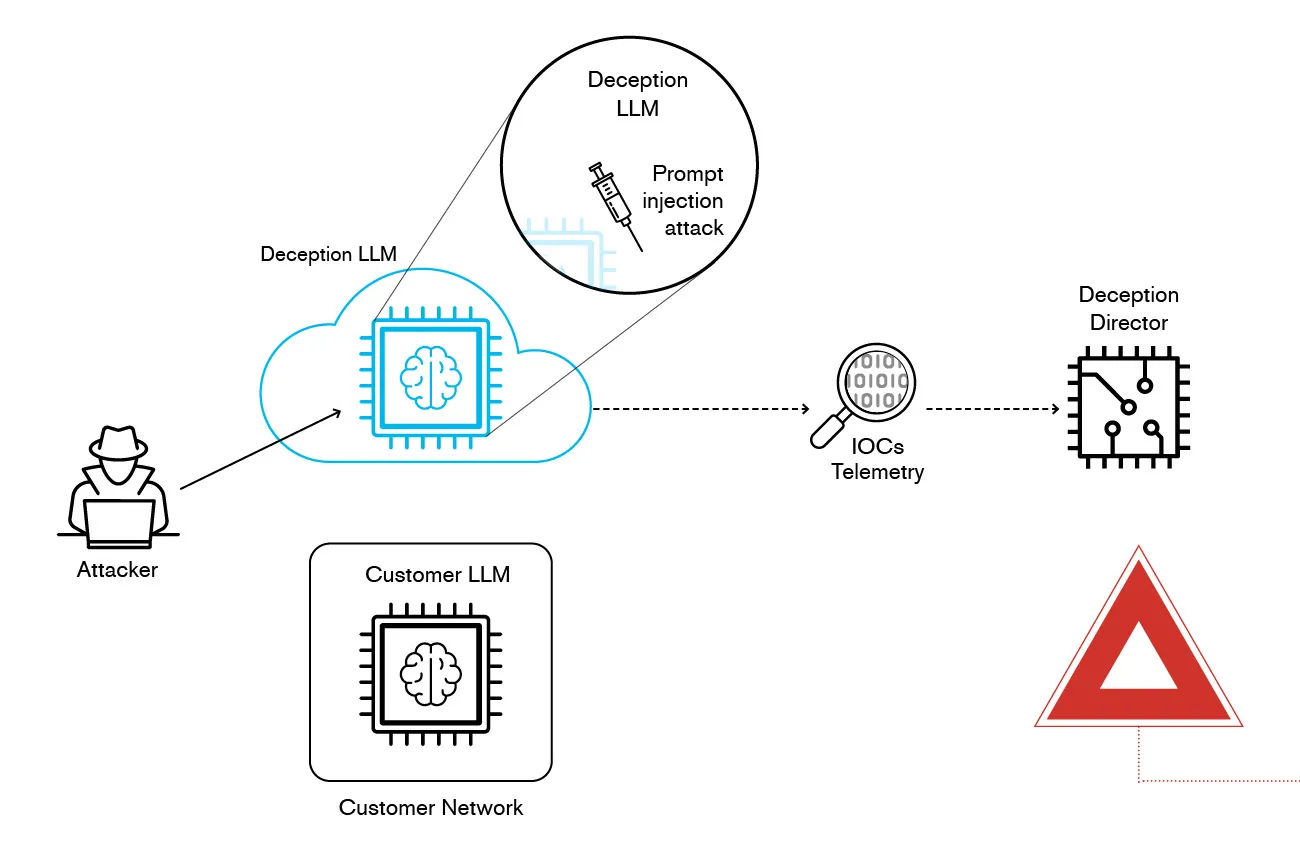
The first step in the campaign is deploying a digital twin of the production LLM within a secure, isolated environment, either on-premises or in a controlled cloud setting. This twin mirrors the real model’s behavior but ensures that any malicious interactions occur within a monitored deception system rather than the actual network. By keeping the twin separate from critical infrastructure, organizations can contain and analyze potential threats without risking real-world exploitation.
To lure attackers, the campaign leverages AI-based honeypots—decoy LLM environments that appear to be legitimate AI assistants. These honeypots are strategically designed to attract adversaries attempting to manipulate the model via prompt injection attacks. By interacting with the fake system, attackers unknowingly reveal their tactics while remaining trapped within a controlled environment.
Once attackers engage with the deception system, real-time telemetry tracking monitors their behavior. The system captures attempted prompt injections, records tactics, techniques, and procedures (TTPs), and identifies Indicators of Compromise (IoCs). This data provides security teams with critical insights into new and evolving threats that may not yet be recognized by traditional cybersecurity tools.
A key advantage of this approach is that it prevents real system exploitation by ensuring that attackers remain confined to the deception environment. Even if they successfully manipulate the honeypot LLM, they cannot escalate access or compromise the actual AI infrastructure. This isolation ensures that the core LLM remains secure while providing defenders with valuable intelligence.
The final phase of the campaign involves extracting and analyzing threat intelligence from the deception system. By logging all attacker actions, security teams can refine detection models and improve defenses against future AI-based threats. The insights gained help organizations strengthen their ability to identify and mitigate emerging prompt injection techniques before they become widespread.
Why the security of LLMs and AI models is vital
As organizations increasingly adopt LLMs for internal operations—whether using cloud-based services (like OpenAI, Google Gemini, or Microsoft Azure) or hosting on-premises open-source models—security risks grow. To mitigate these risks, businesses can deploy localized LLMs (digital twins) to prevent data leakage and maintain control over sensitive information.
Additionally, companies utilizing Retrieval Augmented Generation (RAG), which enhances LLM responses by integrating proprietary datasets, must ensure that their AI systems remain secure. Deception-based defenses can shield these models from unauthorized access while preserving their functionality.
While some enterprises currently run LLMs locally, future cost and infrastructure needs may drive a shift toward cloud-based AI models. Regardless of deployment strategy, implementing deception environments will be essential for safeguarding proprietary AI systems.
A deception-based security approach offers a proactive and adaptive defense against prompt injection attacks. By luring attackers into an isolated AI environment, security teams can neutralize threats before they impact real systems, while also gathering critical intelligence on emerging attack techniques. This strategy ensures that organizations—whether leveraging on-premises or cloud AI models—maintain control over their data, enhance threat detection, and stay ahead of adversaries exploiting AI vulnerabilities

Find out more
To learn more about how innovative AI defense strategies like creating digital twins of LLMs can outsmart exploitation by prompt injection and strengthen your organization’s cybersecurity get in touch with one of our experts.
If you’d like to read about more of the latest AI threats to cybersecurity, download our ebook,From Poisoned Data to Secure Systems: The Antidote to Navigating AI Threats today.